Updated over a week ago
By generating a 'voiceprint', Trint can detect when there is a change in who’s speaking and automatically assign the speaker if you have transcribed them before. This guide will help you use this feature and troubleshoot if speaker recognition isn’t working.
This support guide will cover:
Main functionality
The below illustrates the capability of the tool in its first iteration:
- Easily add or enroll speakers from your transcript: quickly rename speaker labels – such as changing "Speaker 1" to "Judie Smith" – directly within the transcript. You will have the option to remember this speaker for future transcripts.
- Automatic or suggested speakers: we use confidence scores to automatically assign speakers when accuracy is high (85%), or provide suggestions when further review may be needed.
- Organization-wide enrollment: speakers are enrolled at the organization level, making them available across all user transcripts.
- Flexible naming within transcripts: users can rename speaker labels for one or all entries in a transcript (this won’t change enrollment status or affect other transcripts.)
- Efficient searching and selection: when adding or renaming a speaker, a user can type in the search field the enrolled speakers by name. Selecting the field without typing will show any suggested speakers and those already in the transcript.
- Speaker management: enrolled speakers can be enabled, disabled, edited or deleted.
Enrolling a New Speaker

Within a transcript, click on an unrecognized speaker and you'll be given the option to edit the speaker name. This will update the speaker within all entries in this transcript where Trint recognises the same voice.
Once entered, you'll be asked if you want to remember this speaker for future transcripts (see green toggle). This will save it to your organization's Trint account, so only choose this option if you want other colleagues to benefit in future transcripts.

AI Recognized Speakers
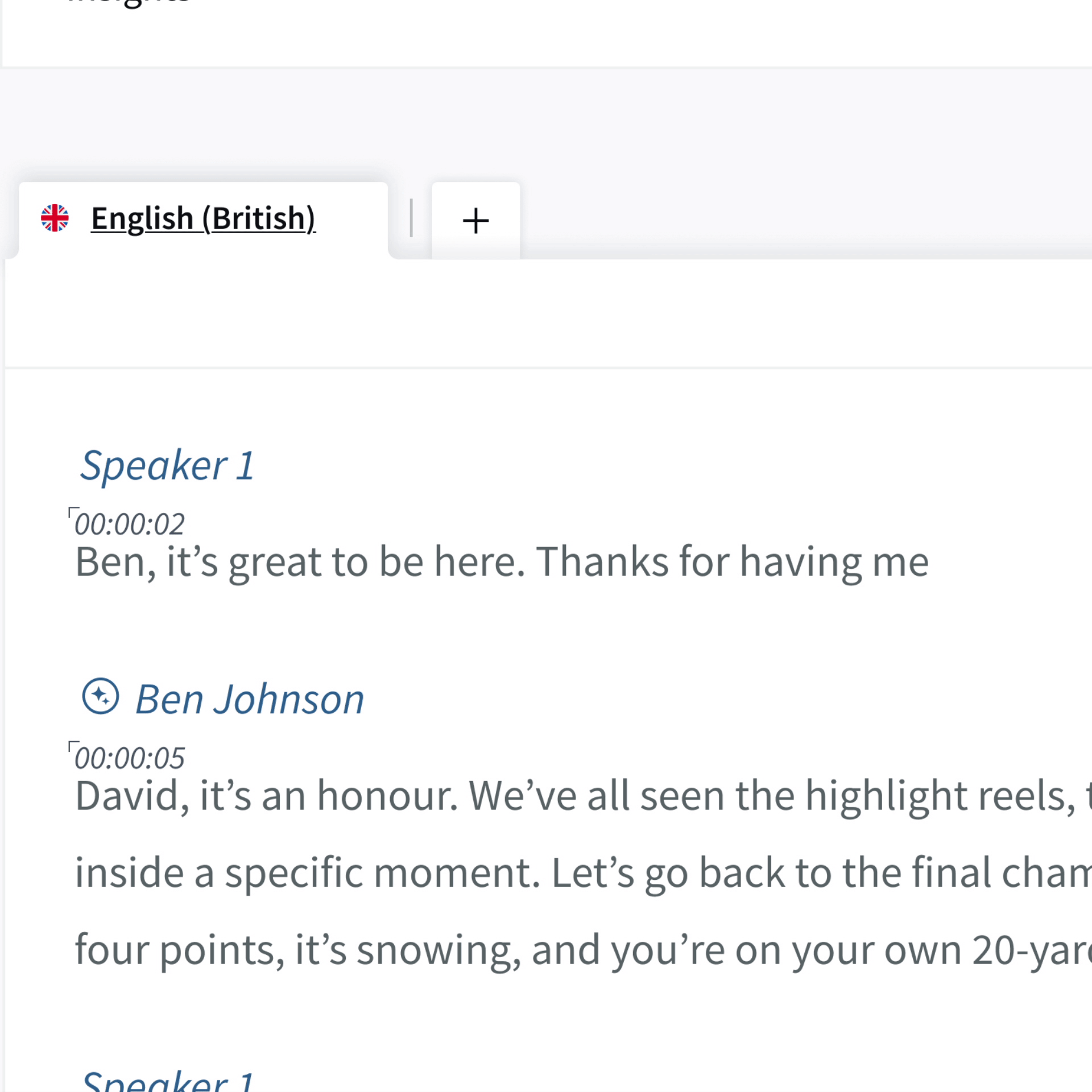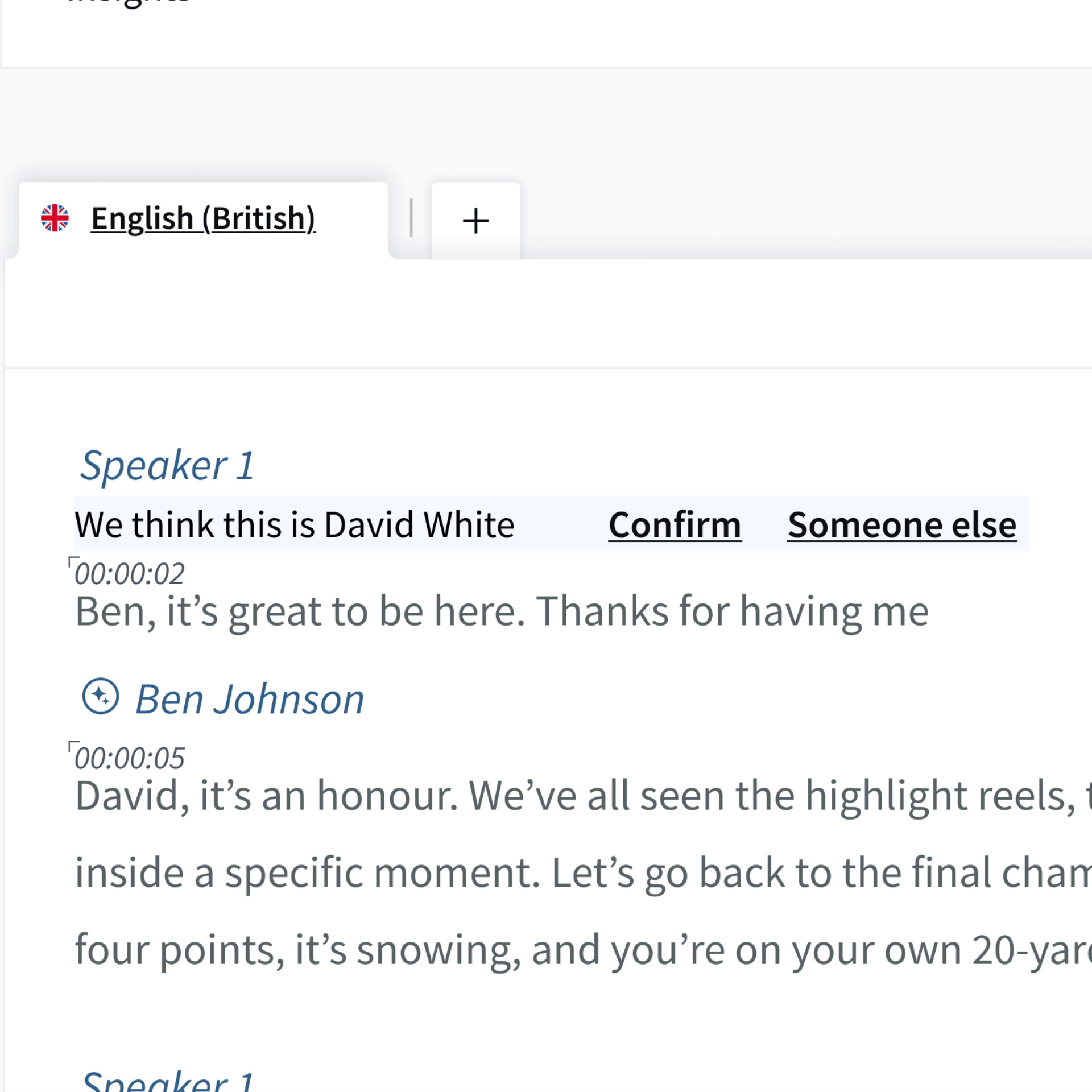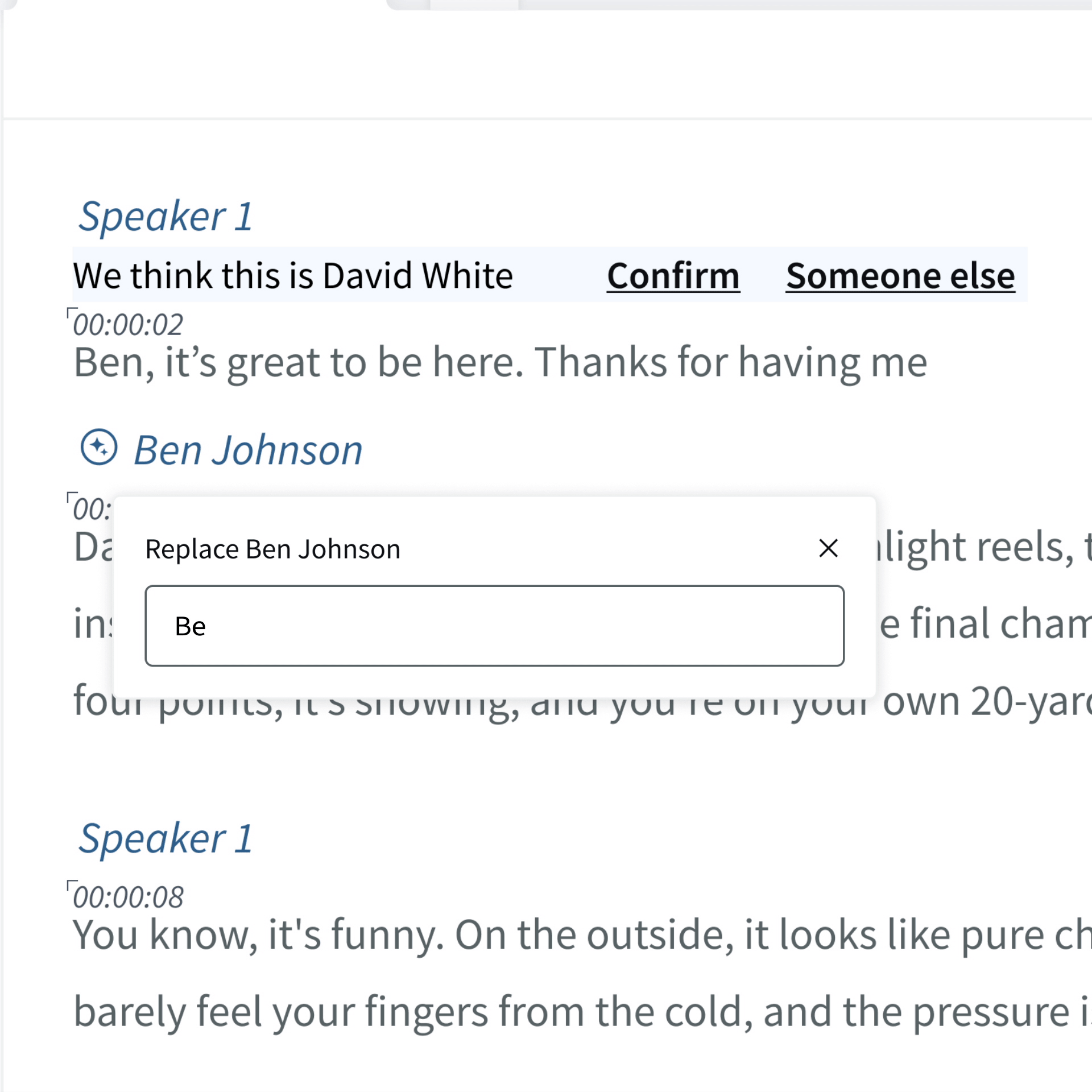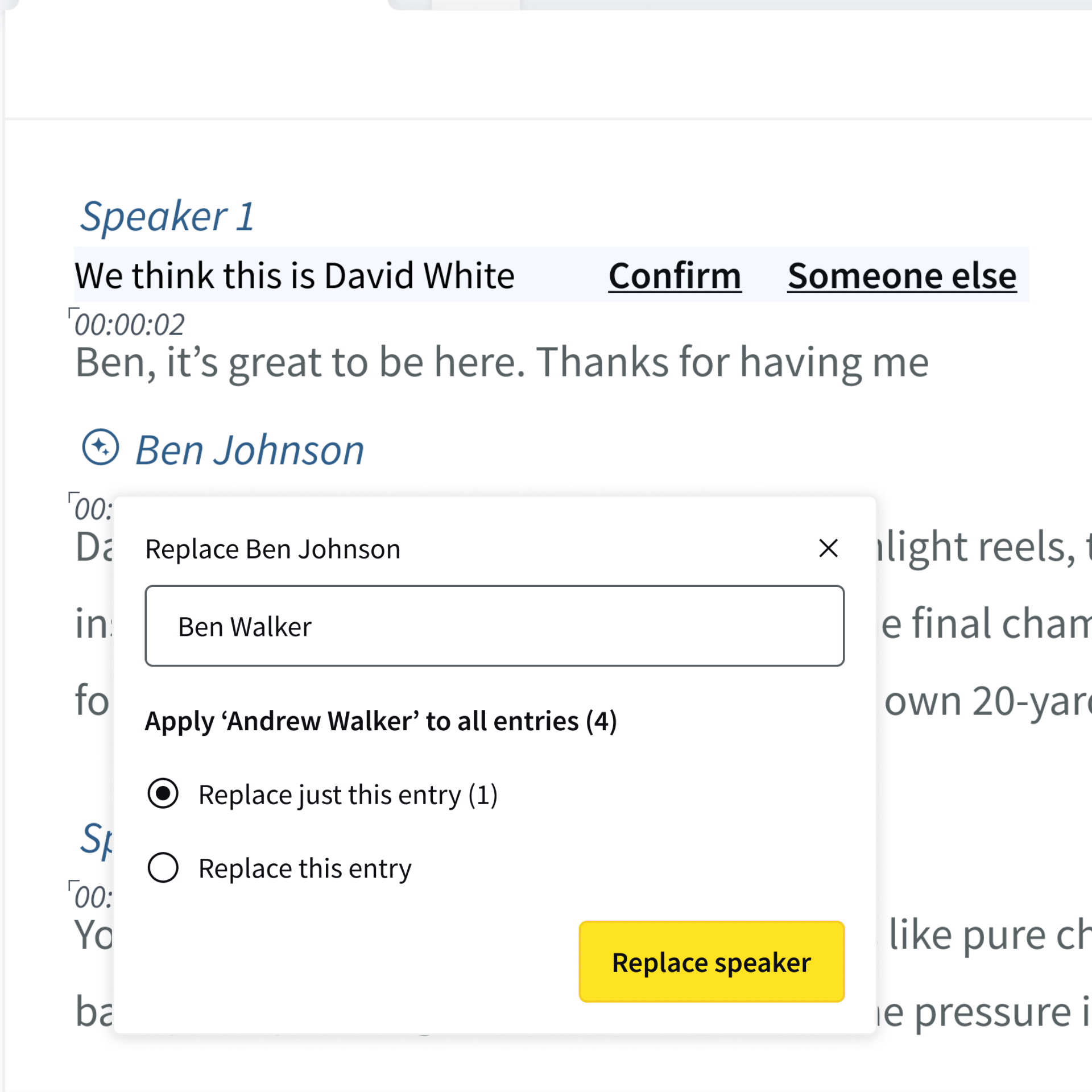
In future transcripts, speakers who have been automatically identified will have an AI symbol by their name. If Trint is less than 85% confident this is the right speaker, it will ask you to confirm the name. If it is correct, click ‘Confirm’.
If this is the wrong speaker you can click ‘Someone Else’ or simply click on the speaker name itself, and a pop-up will appear. You can then add the correct speaker and ask Trint to
remember them if required.
If you need to rename a speaker just click on the name and amend the text. However, this will only update in the current transcript.
This allows you to change the name of a speaker within a transcript. However during this POC, this will NOT change the name or spelling in the database for future transcripts.
The Speaker Management Panel

You can open the Speaker Management panel from the “Speaker” option in the main sidebar of your Trint dashboard. This will show you all of the speakers Trint has remembered for your organization.
There are two ways to filter the speaker list:
- Start typing a name into the search field to automatically narrow results.
- Use the filter dropdown to show only speakers that are enabled or disabled for recognition.
To update a speaker’s name, select it and edit directly in the input field.
These changes will apply to all future mentions of that speaker, however past transcripts will remain unchanged.

Each speaker line includes a toggle you can use to enable or disable recognition for that speaker.

We will be continuing to iterate on this functionality during the testing, so you may see small changes in copy, UX, design or functionality.
Voiceprint privacy and security
Trint's Automatic Speaker Recognition works by generating a biometric 'voiceprint', Trint can detect when there is a change in who’s speaking and automatically assign the speaker if you have transcribed them before.
Trint keeps all data safe and secure by using it only for its intended purpose. This follows suit with Speaker ID, which is to help identify the different speakers apart in your Trint.
Trint generates biometric 'voiceprints' to help distinguish and identify speakers within your audio or video content. These voiceprints are treated as 'special category' biometric data and are only processed on behalf of, and under the instructions of you.
Like all data in Trint, this data is stored securely and with strong protections in place; such as encryption, pseudonymisation, access controls, and ongoing security testing to protect this data against unauthorised access, alteration or loss. At Trint, we never use your data to train models and we do not share it. It remains under your control at all times.
Trint follows strict privacy laws, including GDPR and UK data protection rules, and is ISO 27001 compliant; making sure your data stays secure.
We also treat deletion of speakers the same way as we treat transcript deletion. GDPR deletion is possible upon request.
We hope you have found this article useful. If you have any questions, please reach out to us at support@trint.com and our team will be happy to help.
FAQs
How is my speaker data stored and kept secure?
We understand that voice data is sensitive, so we want to be completely clear that your security is our absolute priority.
To tell speakers apart, our system creates a unique profile - a 'voiceprint' - for each person. We treat this data with the highest level of care, protecting it with strong encryption and strict access controls, in line with top security standards like GDPR and our ISO 27001 certification.
Most importantly, this data belongs to you. It is only ever used to identify speakers for your transcripts, on your account. We will never use your data to train our own AI models, and we will never sell it or share it with anyone. You are always in complete control.
Who has access to the speakers enrolled?
The enrollment of a speaker is global, meaning that any speaker you create will be visible and available for your whole organisation to use. Your transcripts, however, will remain private to you unless you intend to share them. Because enrollment is global, if you rename a speaker, that name will be updated for all your colleagues’ future transcripts as well.
Important Note: Because profiles are shared, any changes you make (like renaming a speaker) will be visible to your entire team. To avoid confusion, we recommend agreeing on a consistent naming style (e.g., "Barack Obama" vs. "President Obama").
Will my previously uploaded files have speakers assigned automatically?
No, it will only work on files you upload after the feature has been enabled for your account. Any content transcribed before this will not be updated.
What languages and content types are supported?
Auto speaker recognition is available for pre-recorded files in English, French, and German.
Please note that realtime transcription will be supported by the end of 2025.
How does the system's accuracy improve over time?
Our auto speaker recognition is a learning system, which means it gets smarter and more accurate the more you use it.
Each time you confirm a speaker's identity in a transcript, you are helping to refine that speaker's unique voiceprint. This makes the system much more accurate at identifying them in future files. Based on our internal research, the system achieves very high accuracy after learning from about five different audio samples of a person's voice.
What should I do if speech is assigned to the wrong speaker?
While our system is highly accurate, no speaker recognition is perfect, especially with challenges like overlapping speech, poor audio quality, or background noise.
If a section of speech is misattributed, you can easily correct it. Simply go into the transcript editor, split the paragraph where the error occurs, and re-assign that section to the correct speaker.
How can I share my feedback?
As this feature is still a work in progress, your feedback is incredibly valuable in shaping next iterations. If you have any suggestions, ideas, or issues to report, please:
- Reach out to your CSM if you are on an enterprise plan
- Or, email the product manager for the team directly at lisa.lavri@trint.com